רבים נוטים בטעות לחפש את שורשיה של אומנות ההצפנה באירופה. למעשה, הספר העתיק ביותר העוסק בקריפטוגרפיה – תורת כתיבת הסתרים - נכתב בעיראק במאה התשיעית לספירה בידי המלומד המוסלמי אל-כנדי (الكندي) ששמו הרשמי המלא מונה לא פחות מ-12 כינויים. אל-כנדי, המכונה גם "הפילוסוף של הערבים", שימש רופאם האישי של שלושה ח'ליפים מבית עבאס וניהל את הספרייה הגדולה של בגדד. הח'ליף הרביעי בתקופתו, אל-מֻתַוַּכִּל הראשון בעל הנטיות השמרניות, לא נטה לאל-כנדי חיבה יתרה. הוא החרים את כל רכושו של המלומד וגזר עליו הלקאה פומבית.
כמה מ-290 ספריו של אל-כנדי עסקו בשיטות הצפנה. אחד מהם תיאר שיטה יצירתית לפענוח צפנים פשוטים על סמך ידע מוקדם על השפה הכתובה. השיטה הזאת, שנקראת "ניתוח תדירויות, הייתה אחד מהכלים החזקים ביותר לפיצוח צפנים מבוססי החלפה, כגון צופן קיסר, במשך מאות שנים לאחר מכן, עד המאה ה-19.
5 צפייה בגלריה
")
כתב במאה התשיעית לספירה את הספר הקדום ביותר העוסק בקריפטוגרפיה. אל-כנדי
(איור: shutterstock)
עוד כתבות באתר מכון דוידסון לחינוך מדעי:
לרדת במשקל ללא מאמץ?
מחסן המידע התורשתי
הבדל של יום ולילה בטיפול בכאב
שיטת הפיצוח
התדירות של כל אות היא מספר הפעמים שהיא מופיעה בטקסט. שיטת ניתוח התדירויות מסתמכת על שתי הבחנות פשוטות: ראשית, בכל שפה יש אותיות שנוטות להופיע יותר מאחרות. התכונה הזאת נקראת סטטיסטיקת השפה. ושנית, בטקסט מוצפן שכל אות בו הוחלפה באות אחרת או בסימן קבוע אחר, כל סימן יופיע בדיוק אותו מספר פעמים שהאות האמיתית הופיעה בטקסט המקורי, שכן היא החליפה אותה. לכן, אם נמצא את התדירות של כל סמל בטקסט המוצפן, נוכל להתאים את הסמלים לסטטיסטיקת השפה ולגלות בסבירות גבוהה יחסית מהי האות האמיתית המסתתרת מאחורי סמל זה או אחר בטקסט המוצפן.
כדי לאסוף סטטיסטיקת שפה כזאת צריך לצבור כמות נכבדה של טקסט, לעבור אות אחרי אות ולספור כמה פעמים היא מופיעה. לפני הופעת המחשב המודרני זה היה ללא ספק תהליך סיזיפי ומתיש. וכך, כשמחשבים את תדירות האותיות במהדורה עברית של הספר "הנסיך הקטן", ללא הפרדה בין אותיות סופיות לאותיות רגילות, מתקבלת הטבלה הבאה:

ככל שהטקסט המנותח ארוך יותר, כך הסטטיסטיקה תהיה מהימנה יותר ותעיד על תכונות השפה. הטבלה שלנו עצמה לא לגמרי מדויקת, כיוון שמטעמי נוחות הערכים שבה מעוגלים למספרים שלמים. ובכל זאת אפשר להבחין בה בקלות בדומיננטיות אותיות התנועה אהו"י, שתדירותן עולה על זאת של כל העיצורים פרט למ'. בשפות לטיניות התופעה בולטת עוד יותר עקב העובדה שכל מילה בהן חייבת לכלול אות תנועה אחת לפחות. לפי התדירות שמצאנו, האות השכיחה ביותר היא י' (דרגה 1), אחריה ו' וה' (דרגה 2), א' ומ' (דרגה 3) וכן הלאה
כך נפצח
יש בידינו משפט שהוצפן באמצעות החלפת כל אות בסמל. נבחן את המשפט המוצפן הבא:
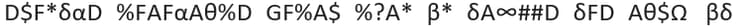
אם נמנה את הסימנים נקבל את טבלת התדירויות הבאה:
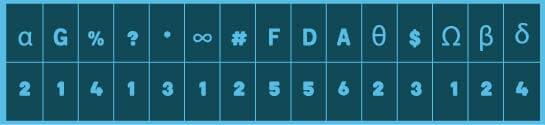
הסמל שמופיע הכי הרבה פעמים הוא A. נוכל אם כן לשער במידה רבה של ביטחון שהוא מייצג את האות י', שכן היא האות השכיחה ביותר בסטטיסטיקת השפה. זאת כמובן השערה בלבד, כי איננו יודעים עד כמה הטקסט הקצר שלנו משקף את תדירות האותיות בשפה כולה, אך מדובר בנקודת פתיחה טובה. באופן דומה, סביר להניח אך לא ודאי שהסמלים D ו-F, שנמצאים בדרגה השנייה, מייצגים את האותיות ו' וה', וכן הלאה. מאחר שהטבלה כוללת רק 15 סימנים, אפשר להסיק שהתדירות של שבע מ-22 האותיות בשפה העברית היא 0 במשפט המקורי.
ההתאמה בין הסמלים הנפוצים ביותר בטקסט המוצפן לתדירות האותיות בשפה היא אמצעי עזר חשוב, אך הוא אינו מספיק לבדו. בידי מנתחי תדירויות נמצאות טקטיקות נוספות להמשך תקיפת הצופן. לדוגמה, עליהם להכיר את מבנה המילים ואת מבנה המשפט בשפה. בעברית למשל נפוצים צירופי הרבים והרבות, "ים" ו"ות" בסופי מילים, ואילו אותיות השימוש מש"ה וכל"ב שכיחות בתחילתן. שילוב של תובנות כאלה עם ניחושים מושכלים של ניסוי וטעייה ועם חיפוש אחרי מילים שלמות שיאפשרו להתאים סמלים לאותיות גם במילים שעוד לא זוהו, אמור לאפשר למפענחים והמפענחות המיומנים לפרוץ את הצופן כולו.
אם כן, פיצוח צפנים אינו רק טכניקה, אלא אומנות, ושיטות כמו ניתוח תדירויות הן קיצורי דרך מועילים במלאכה קשה ומורכבת הרבה יותר. לא בכדי מפצחי הצפנים הטובים ביותר של בריטניה במאה ה-20, כמו אלן טיורינג, היו שילוב של מתמטיקאים, פותרי חידות ובלשנים. כדי לנתח צופן דרושות יצירתיות, הכרה מעמיקה של השפה ונחישות רבה.

רמז: אל כנדי מופיע במשפט
ליאור ויצהנדלר, מכון דוידסון לחינוך מדעי, הזרוע החינוכית של מכון ויצמן למדע